With its brand new Data Hub, EisphorIA brings a new and refreshing way to search for critical information swiftly and smoothly in any legal data sets thanks to a subtle combination of AI, speed and modern design.
Our previous blog (see here) discussed the major benefits of self-supervised NLPs models and what they bring to “open data” and why there is a perfect match: not only they overcome the lengthy and expensive tagging/labelling process, but they also achieve an increased level of relevance and flexibility compared to supervised approaches.
This was the forerunner of a large-scale initiative undertaken by EisphorIA in relation to “open data” ...
And January 6 2021 was a big day with the launch of our Data Hub, a platform gathering multiple legal libraries created from data openly released by public authorities!
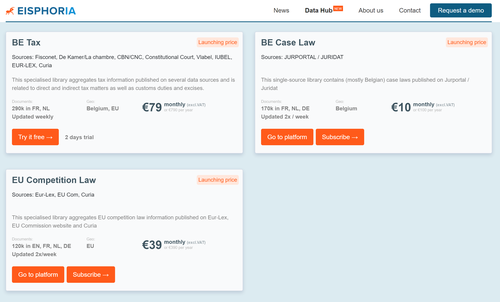
Our vision is to make this Data Hub a reference platform for the legal market where lawyers can find in a single place different 'open data' sets, particularly interesting for their practice, and whose accessibility is greatly increased by our solution.
A new search experience that invites to adopt a fresh view
Let’s be clear: our goal is not to propose conventional libraries, like those proposed by Wolters Kluwer, LexisNexis and other players. For the simple reason that each of our libraries is the result of an automated deployment of our solution without any human supervision (e.g. no “human” classification, no “human” labelling of the information).
We are playing on a different field!
And, our Data Hub may be the first time you are confronted with a disruptive search experience brought by real artificial intelligence. Even if there are some common features between our libraries and conventional libraries, you should apprehend ours with a fresh view.
And yes, search relevance is the critical element on which we want to be judged!
“What we are proposing is a totally new search experience, a totally new way to conduct technical searches within the dataset, resulting from the assistance of artificial intelligence. You can of course still conduct searches the traditional way but you are now equipped with plenty of other search functionalities not available in conventional libraries.”
Among others, you:
- Have more flexibility in the manner the request is formulated (we are not only playing with synonyms, similar words but also with the context expressed - see here),
- Can initiate a search from relevant paragraphs identified in a document,
- Can review documents based on an automated relevance classification and relevance quantification,
- Have the guarantee the full content of documents is explored when initiating their requests,
- Etc...
Contrary to conventional libraries, you are not forced to follow the restrictive search criteria imposed by the publisher but you can freely conduct and parameter your searches as you want, and this with significantly more relevance and less iterations.
A Showcase for other uses cases
Our Data Hub is the result of 2 guiding principles from which we have never deviated, i.e.:
- Ensure an extremely easy, efficient and autonomous deployment of our solution (metaphorically, a library can be created from any set of textual data by a simple push of a button), and
- Ensure a hyper fast processing of requests - simple or complex - formulated by the user to surface the most relevant information.
Hence, beside our vision to render ‘open data’ even more accessible, our Data Hub also constitutes a showcase of this new approach powered by a new generation of algorithms performing a deep contextual analysis of every document included in the data set which allows users to efficiently navigate and search for the critical information.
“The Data Hub is an illustration of our technology applied to public data sets and we can easily transpose this to any kind of data sets (external or internal to your organisation, for instance, when searching your knowledge management (see here) ou when investigating client cases or mailboxes (see here).”
This is why we are encouraging our users to experiment with our contextual search and assess the relevance of the results. All of this in a modern interface where user experience design is paramount.
What’s next for the Data Hub: create public libraries at a high pace from relevant legal ‘open data’
Looking forward, the Data Hub will house libraries:
- At our own initiative, i.e. libraries created from datasets that we have already identified or will identify, and/or
- Based on open consultations, i.e. libraries created on the basis of feedback received via our ongoing survey hosted on the Data Hub (with preselected datasets and the possibility to indicate to us those you consider important for your practice).
The Data Hub will therefore welcome new libraries on a very regular basis.
Starting now with 2 specialised libraries (one for Belgian tax, one for EU competition) and 1 specific library (Belgian case law), we plan to house about ten libraries in the coming 2-3 months. And, we will particularly target any new released datasets. So, do not hesitate to report us anything new in this context.
Curious to know more: visit hub.eisphoria.com. We will be delighted to welcome you in our community!
