
While in the past traditional search engines worked with statistical models built around keywords and links, we now see a shift in content discovery from keyword based search to discovery based on context and intent thanks to the adoption of Natural Language Processing (NLP). NLP basically focuses on transforming natural language into machine-computable information.
Keyword search is important but is restricting and in some occasions could be misleading (i.e. think the word “bank”, does it mean the bank where you can sit at the park or the bank where you have your money?,…). Since it doesn’t collect enough information about why you are searching a particular keyword, it will generate (too) many possible answers which incurs you a fastidious work of filtering out all the results that are not relevant to you. Worse, sometimes you are not even sure which keywords to type in the search box to get the right results.
“We believe without contextual analysis, you can not have the best search experience“
This is where contextual search comes in and is also one of the key benefits that Natural Language Processing has brought to the market thanks to the availability of large corpus of texts, on which the non-supervised machine learning approaches can study and thus have a better understanding of the way we express things.
The solutions we build at EisphorIA are on top of the most recent developments of NLP, and are particularly focusing on contextual search which we consider as a “must have” to address the legal research needs. We believe without contextual analysis, you can not have the best search experience.
And this is quite “simple” to understand in our opinion, since the search experience we want to obtain is one that transposes the natural method that we all follow in any research (sort of biomimicry;).
“The formula: words + concepts + context = unequaled relevance“
What we offer is an increased way of carrying out research: the words, the concepts obviously still have an important role to play but it is context which determines the rules of the game. In other words, the formula: words + concepts + context = unequaled relevance. A real paradigm shift.
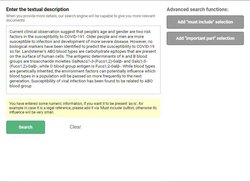
If you think twice, this way of proceeding is natural and logical: it only transposes the method that dominates in any documentary research. In fact, for an information to be considered relevant, not only it has to deal with the words and concepts sought, but also it must be treated in the context(s) that interests the searcher.
And, speaking about the legal sector, this is even more crucial when data needs be crunched, monitored based on contextual relation. Particularly, we may think about dispute resolution or competition. In such situations, NLP assistance provides a true competitive advantage for discovering the relevant content incredibly fast. Indeed, if our algorithms obviously do not replace the critical analysis of the lawyer, they assist in a formidable way for:
- The selection of the relevant documents, by excluding documents with minor interest;
- The discovery of the content of relevant documents, by identifying sections that are contextually linked with the search query;
- The organization of relevant documents, by classifying and creating bridges between documents that present a certain level of contextual closeness;
- The apprehension of counter party argumentation, by allowing to instantly retrieve the source document and addressing all documents that are contextually linked to the argumentation.
This is why the experience we offer is not only new but is also extremely powerful for the research and analysis of documentation. A clear “fast lane to critical information”, making us unique on the market.
